无封面
「大模型项目」一文了解如何评测大模型效果?10000字+
为什么大模型需要评测?
对大模型评测,是为了发现问题以及明确改进路径。
评测可以精准定位大模型的不足,明确大模型的改进方向。通过系统化、量化的问题分析,可以为模型优化提供依据。
但是大模型的评测并不容易,尤其是如何全面、系统的量化模型问题,不仅仅需要技术能力,也需要系统的评测框架。不过也不用太担心,其实跟传统的机器学习等算法评测框架类似,只是多了一些评测纬度而已。
接下来将从6个方面来讲解大模型的评测:
一、大模型评测体系
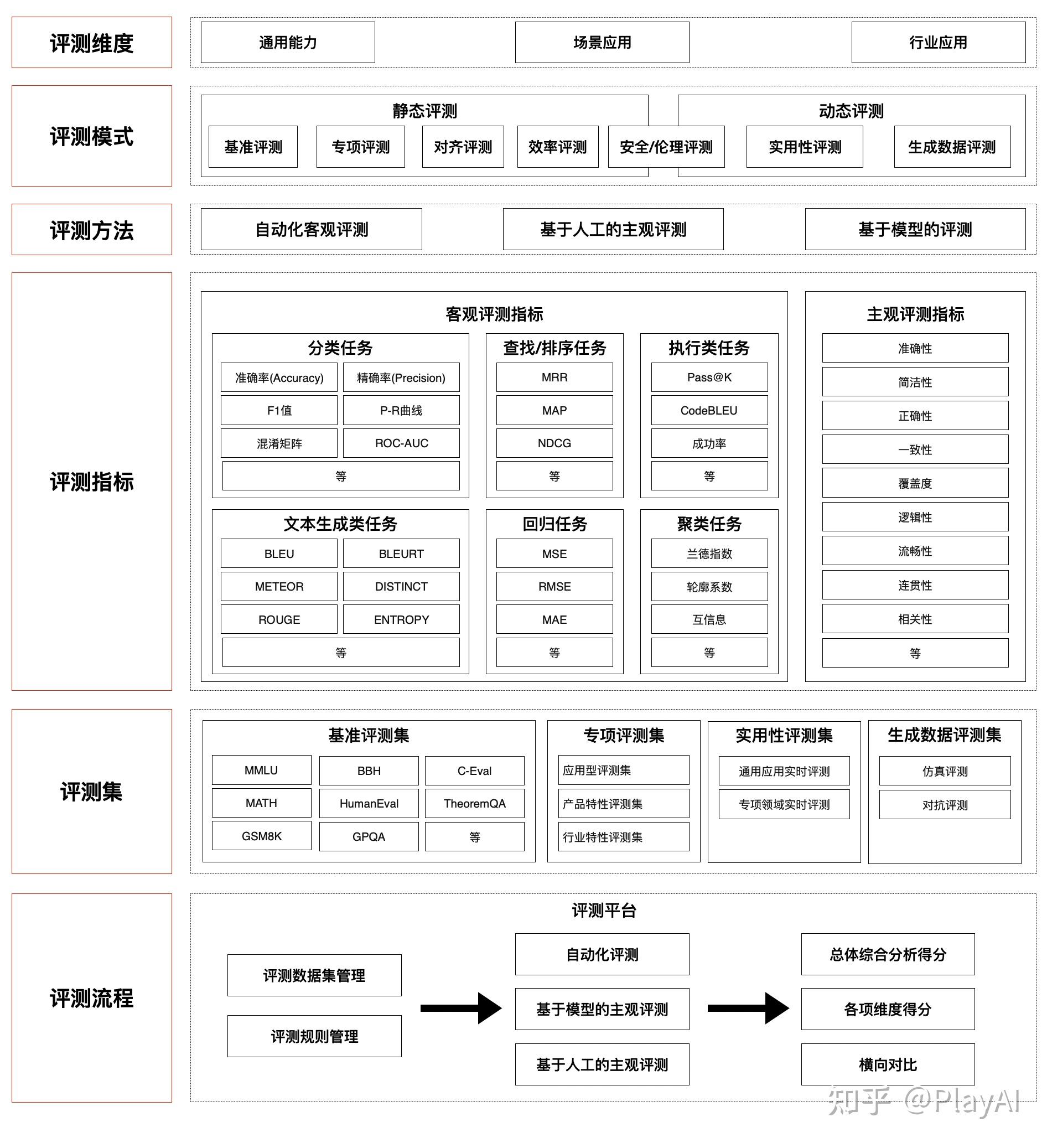 用一张图先总结一些,大模型的评测体系。大模型的评测可以分为3个关键组成部分:“评什么”(维度、指标、数据)、 “怎么评”(模式、流程)、 “评到什么程度”(主客观指标、基准与专项评测集)。
用一张图先总结一些,大模型的评测体系。大模型的评测可以分为3个关键组成部分:“评什么”(维度、指标、数据)、 “怎么评”(模式、流程)、 “评到什么程度”(主客观指标、基准与专项评测集)。
接下来我们详细拆解一下,每个模块的细节。
二、大模型评测维度
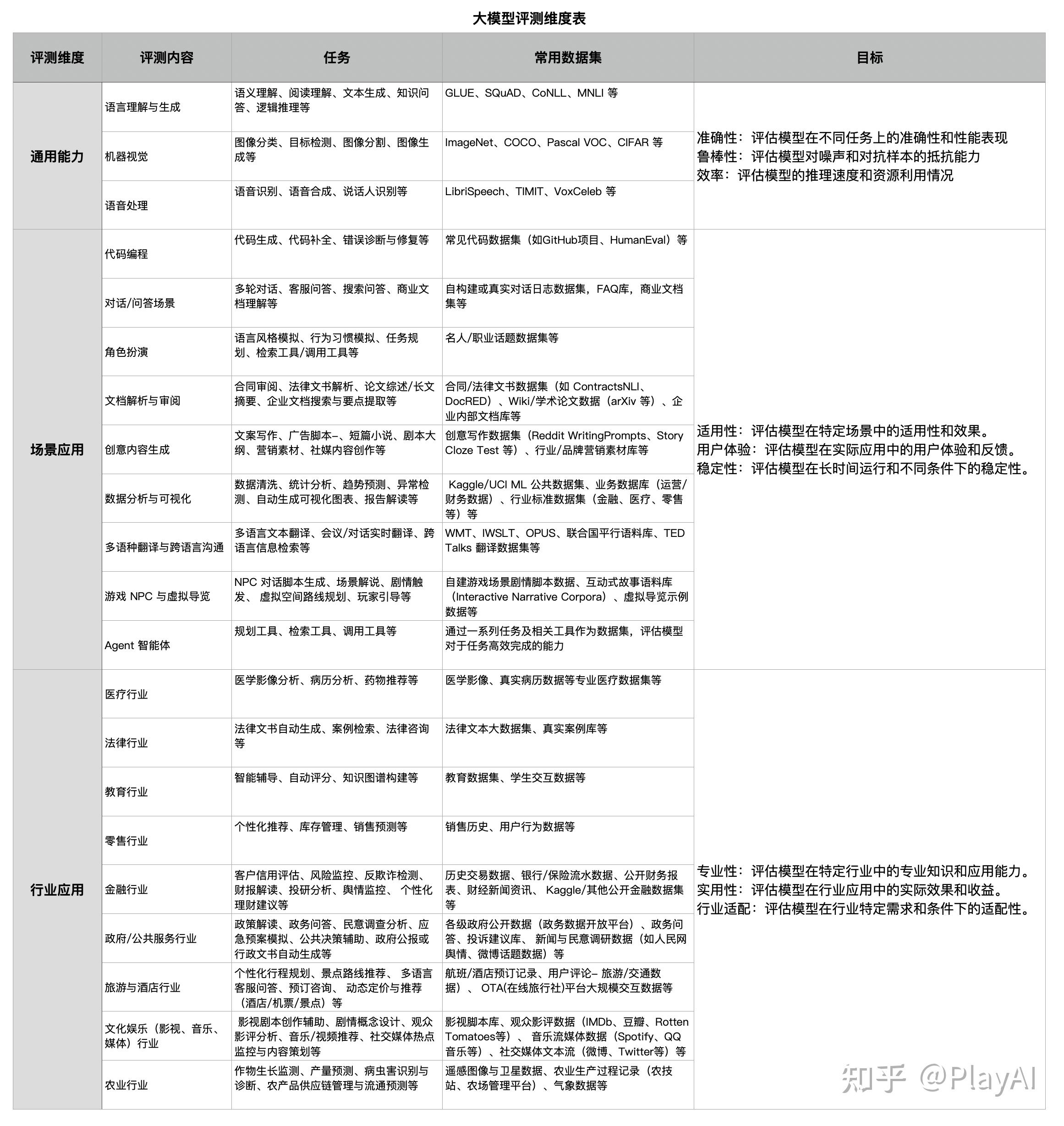
大模型的评测维度,一般可以分为3个,分别是通用能力、场景应用、行业应用。
具体内容可以查看下面的表格。
三、大模型评测模式
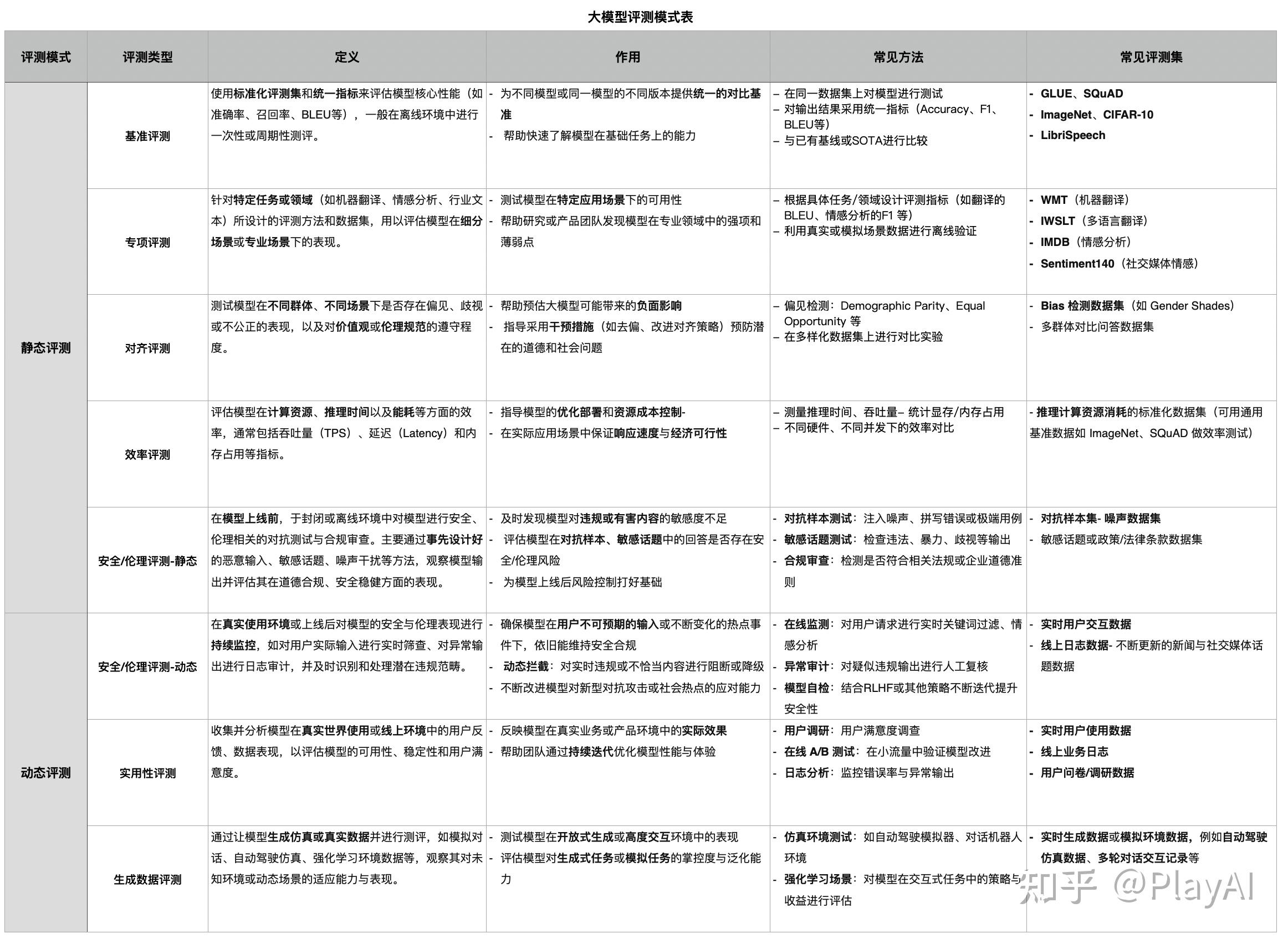
静态评测,指的是用固定数据集评估模型的性能指标。
动态测评,指的是模型实际使用反馈。
详细解释可以看到下面表格。
四、大模型评测方法
模型的评测方法,主要有3种,分别是:客观性评测、基于人的主观性评测、基于模型的评测。
详情见下表。
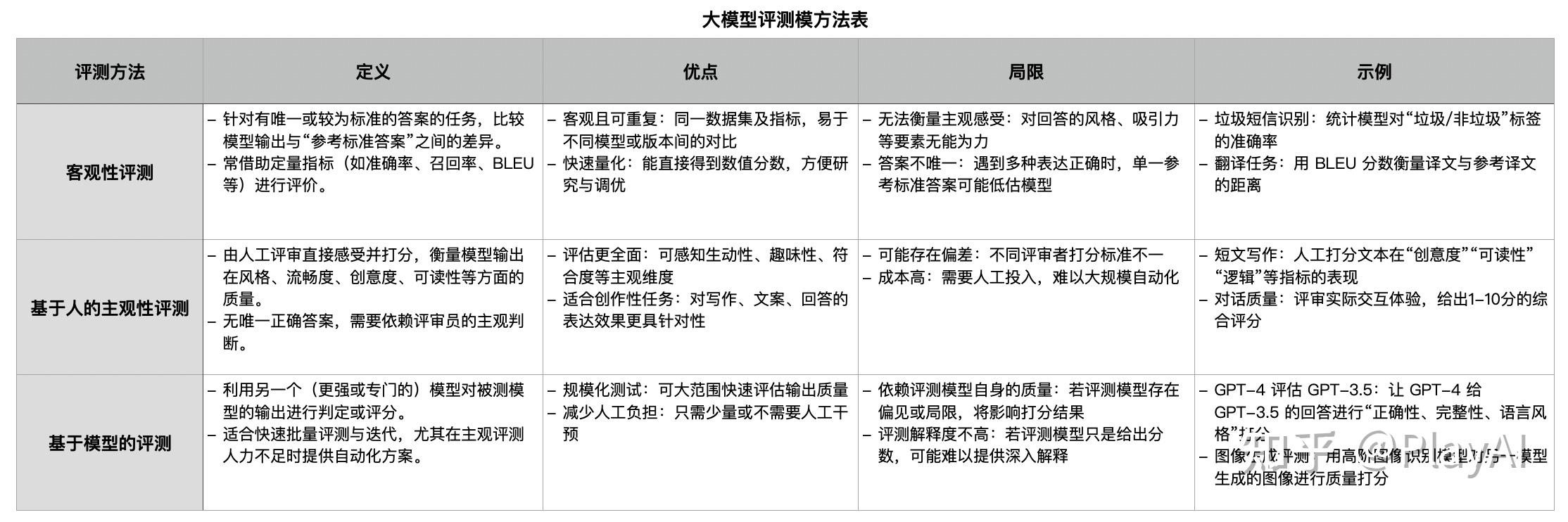 • 客观性评测:有标准答案可对比,适合“对错”或“是非”的判断,如分类、问答、翻译等;
• 客观性评测:有标准答案可对比,适合“对错”或“是非”的判断,如分类、问答、翻译等;
• 基于人的主观性评测:没有唯一标准,需要评委主观感受,如写作风格、表达效果、创意度等;
• 基于模型的评测:用更强或专门的模型来评估被测模型输出,可减轻人力负担,但依赖评测模型自身的可靠性。
这三类方法通常互相配合,用于评估大模型在不同层面的表现,从准确性到可读性、再到可扩展性和创意度等多维度获得全面的质量衡量。
五、大模型评测指标
大模型的评测指标,主要分为客观评测指标、主观评测指标。
1、客观评测指标
请看下方表格。
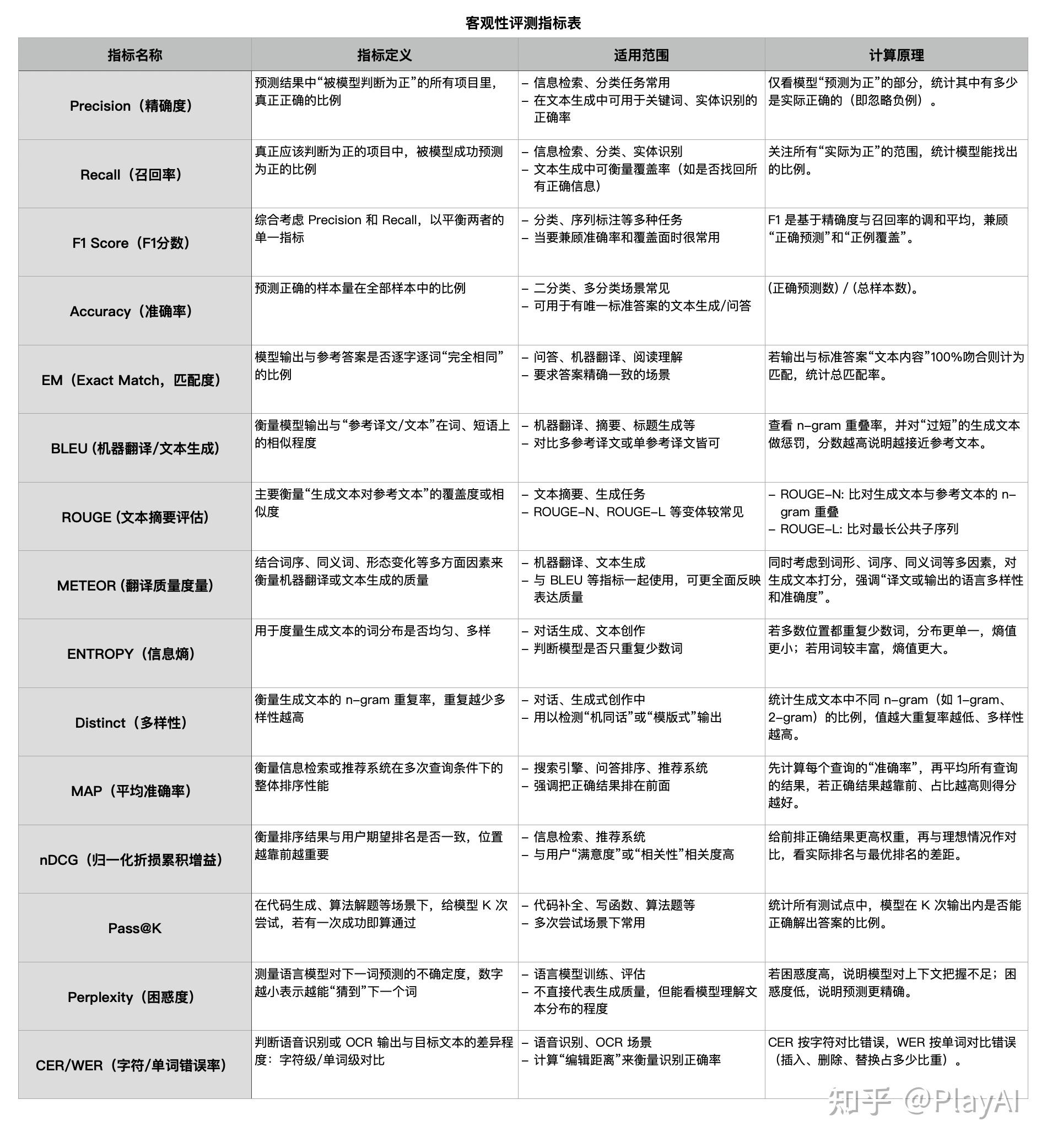
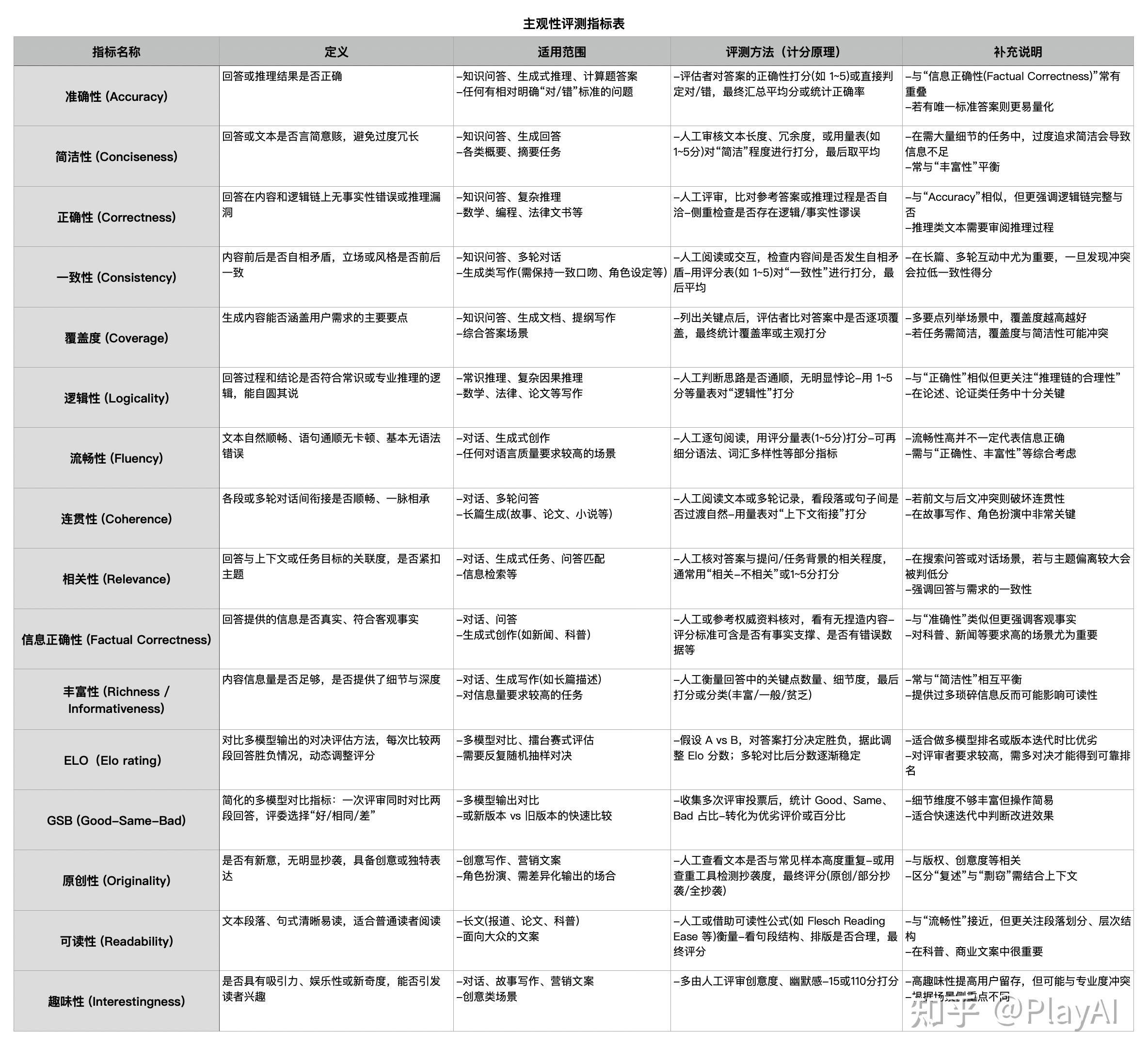
2、主观评测指标
请看下方表格。
六、大模型评测集
大模型评测集,我们可以寻找网上公开的评测集,也可以自己进行构建。
1、网络公开常用基准评测集
详见下表。
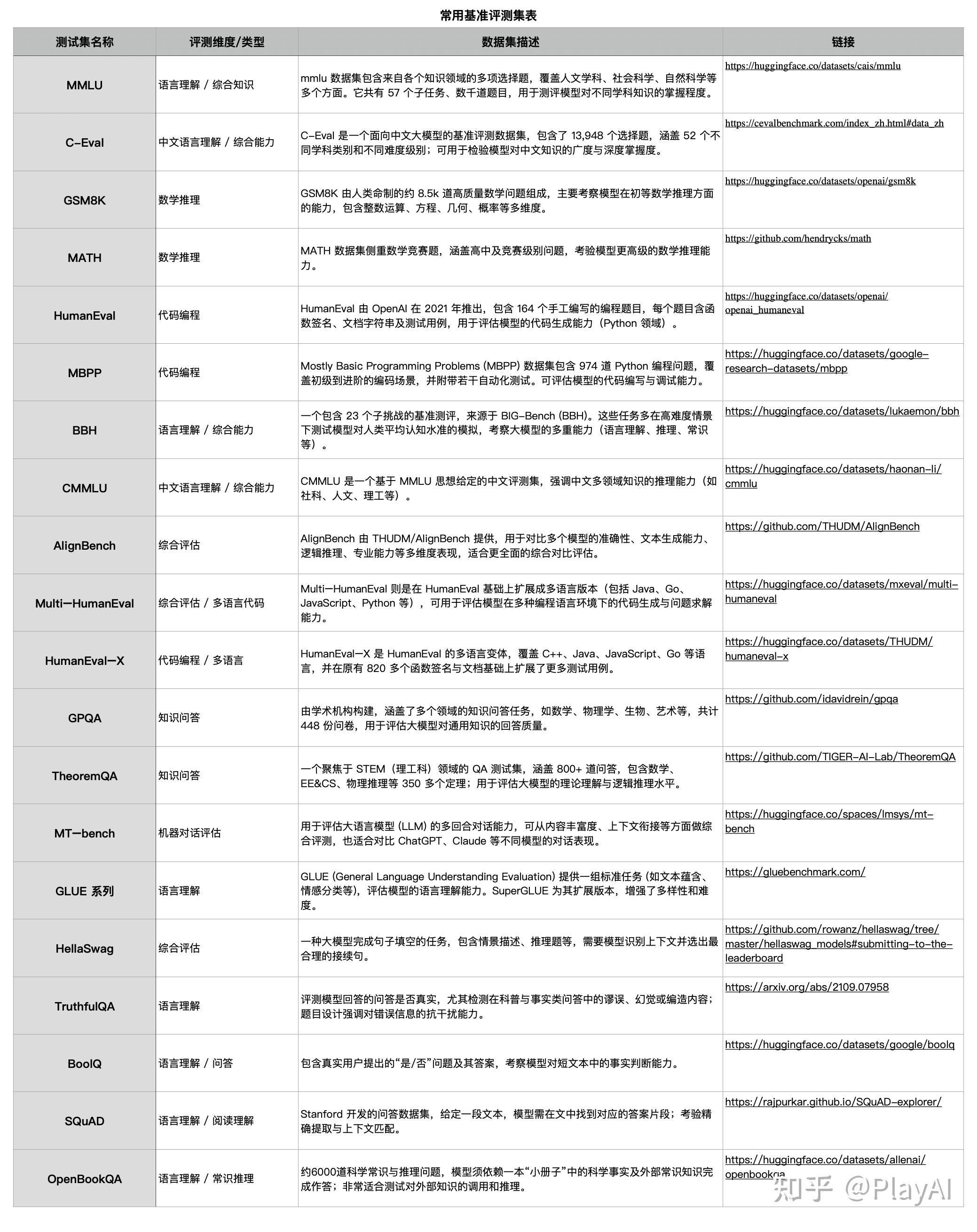
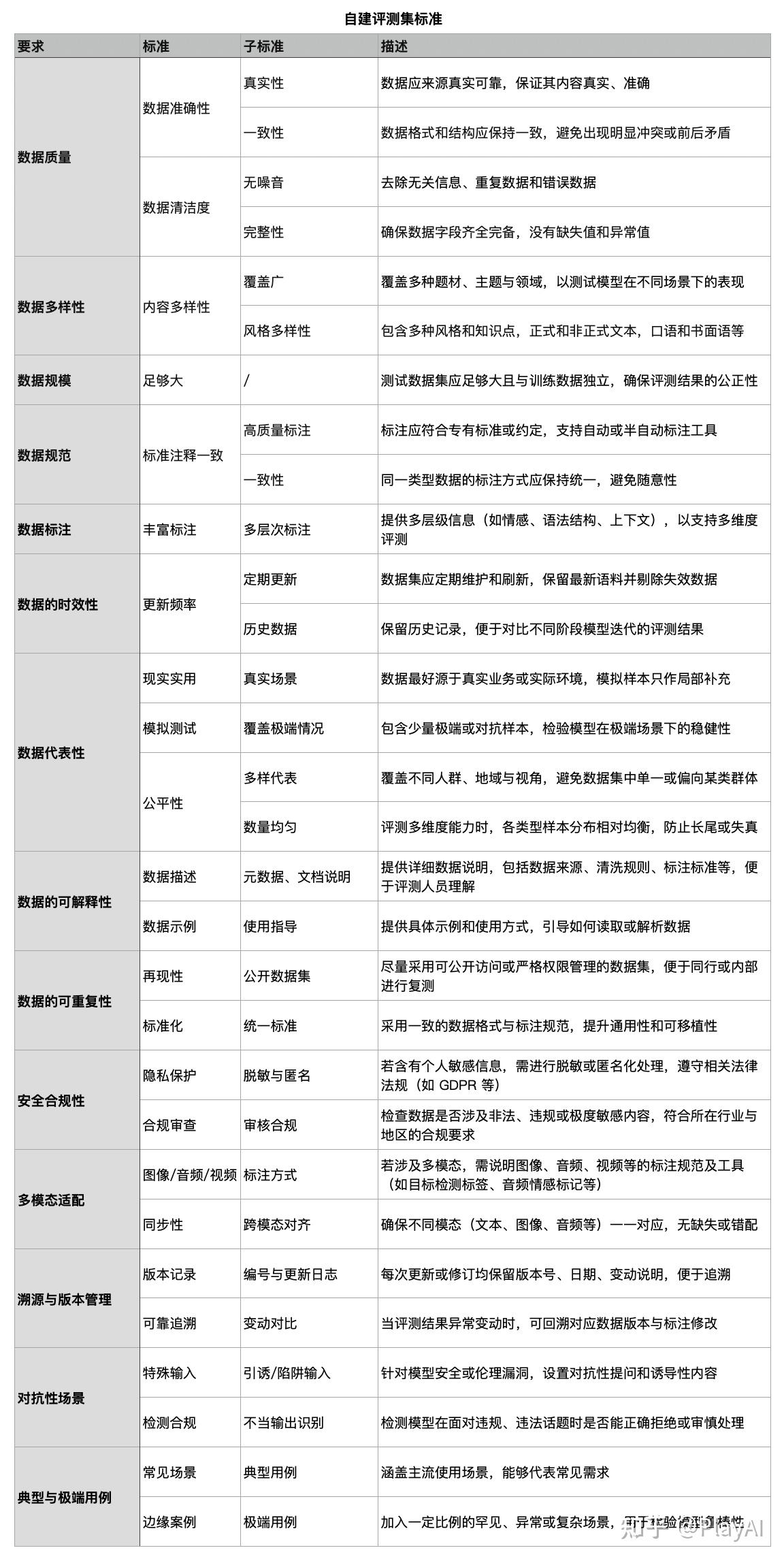
2、自建评测集(专项评测集、实用性评测集、生成数据评测集)
因为每家公司业务场景都不一样,并且很多数据是不能公开的,因此需要建立内部的评测集,建立内部评测集,可以参考下面的标准进行建立。
专项评测集、实用性评测集、生成数据评测集,基本上都是公司自建,也可以向第三方公司进行采购(非常贵)。
七、评测方案举例
1、需求背景
业务场景:
1)手机电商平台或官方商城会收到大量用户对产品的评论和评分,评论内容质量高低不一。
2)平台希望能将“优质、有参考价值”的评论优先展示给潜在消费者,从而提升购买决策效率和用户满意度。
核心目标:
1)建立一套“评论打分”或“评论质量判别”模型,对海量评论进行分级处理(如评分、分类、过滤等)。
2)选出“优秀评论”优先呈现,并且保证对用户的多样化需求(如正面/负面、简洁/详细等)都有兼顾。
应用价值:
1)帮助潜在消费者快速获取有用的信息,减少繁琐的评论浏览成本。
2)为商家提供真实、有效的用户反馈,便于后续产品优化和售后服务提升。
3)促进良性的社区氛围,激励更多用户写出更有价值的评论。
2、评测维度
1)通用能力:语言理解与生成
关注点: 模型能否准确理解并评估用户评论的语义、情感与逻辑;能否对评论做合理的生成式概述或要点提炼。
2)场景应用:用户评论评分
关注点:关注模型是否能根据标准正确的对用户评论进行打分。
3)行业应用:零售 / 电商
关注点: 用户评论通常涉及价格、体验、售后、促销等多维度;还可能有跨品牌或跨机型对比内容,需要模型对产品属性和行业特性的理解。
3、评测模式
1)静态评测(离线测试)
在历史评论数据上进行一次性或周期性的离线跑分,检测模型对已知评论的分类或打分准确度。
2)动态评测(在线监控)
模型上线后,实时或周期性收集新评论的数据和用户行为反馈(如点击率、阅读完成度、是否被举报等),评测模型在线实际表现并进行滚动改进。
4、评测方法
- 客观性评测
有明确参考标准或“地面真值”(如标注好的“优质评论”标签)可供对比,通过准确率、F1 等数值指标量化模型效果。
- 基于人的主观性评测
让人工评审员对模型输出的“优质评论”进行打分或排名,看其与人工判断的优劣评论是否一致。
- 基于模型的评测
用更高级或专门的评估模型,对被测模型选出的“优质评论”进行判定或评分(如 GPT-4 、豆包等)。
5、评测指标
1)Precision / Recall / F1(在优质评论检测场景中)
设定“优质评论=正例”,衡量系统在打分阈值后选出的评论中正确率(Precision)以及应选的优质评论被选中的覆盖率(Recall),并用F1综合评估。
2)Accuracy(整体准确率)
若有多档评分(如 1 星 ~ 5 星),可用准确率考量模型在各档评分与人工标注的一致程度。
3)NDCG(Normalized Discounted Cumulative Gain)
适用于排序场景:若模型对评论进行排序,再与“人工排序”对比,看前排展示的评论是否与理想排序相符。
4)主观评分(MOS 或 Likert)
人工读评模型选出的高质量评论,用问卷或量表(1~5)评估“内容深度”“有用度”等,取平均分(Mean Opinion Score)。
5)用户行为数据(动态评测)
• CTR(Click Through Rate):用户对推荐评论的点击率;
• Engagement:评论阅读时长、点赞、回复等;
• 投诉/举报率:若优先展示评论引发负面反馈,可视为模型效果差。
6)覆盖率 / 多样性指标
检查推荐出来的评论是否均为一致立场或单一类型;可统计“正面/负面评论比例”“短文/长文比例”等。
6、评测集构建
1)数据来源
历史评论库:从官方商城/电商平台/社交媒体中抓取大量已发表的手机产品评论;
用户行为日志:包含点击、点赞、投诉、分享等数据,可辅助动态评测。
2)标注方式
人工为部分评论标注“优质 / 普通 / 劣质”标签,或更细分档次(1~5分);
可能还需要标注评论的“情感极性”(正面/负面/中性)和“主题标签”(如续航、外观、性能、价格等)。
3)规模 / 覆盖
选取不同机型、不同时间段的评论,避免数据分布偏差;
包含多种语言或方言(若业务跨地区),并保留一定比例的噪声或极端评论做稳健性测试。
4)拆分与更新
训练集 / 开发集 / 测试集,或直接在已有模型基础上以“测试集”+“在线流量”结合评估;
定期添加新机型或新周期评论,持续更新评测集。
7、评测流程
1)静态评测阶段
1-模型训练或加载预训练模型,基于历史评论集进行微调;
2-在离线测试集上评测:计算Precision、Recall、Accuracy等;
3-调参或改进模型:根据结果不断修正打分阈值或模型结构。
2)上线灰度及动态评测阶段
1-灰度发布:将评论打分模型作用在部分流量上;
2-采集用户反馈:点击、举报、停留时长、二次交互(是否点赞或回复)等;
3-定期评估与调优:对用户反馈做数据分析,调整策略(如阈值、过滤规则)或重新标注意见,形成新一轮离线评测与在线更新的闭环。
3)定期回归测试
每个版本升级或模型迭代后,重新在固定测试集和实时流量中做对比评估,确保性能没有出现回退。
八、案例举例
案例场景:某手机电商平台在“双十一促销期”每天涌入上万条评论,其中包含大量水评、简短无意义评论或重复刷单评论,也有极少数高质量的使用心得。
实施步骤(简化版):
1)从过去三个月的评论中,抽取 2 万条人工标注为“优质/普通/劣质”三档,作为离线评测集;
2)使用基座语言模型(LLaMA/ChatGLM/Qwen等)进行评论打分训练,在离线评测时达成 F1=0.85;
3)在灰度流量(10%用户)上线,观察真实用户对“已打分为优质评论”置顶展示的点击率、点赞率提升 20%,举报率保持在较低水平;
4)观察一周后,收集到新的用户评论数据,将其与已标注评论混合形成增量测试集,不断迭代打分策略;
5)最终在双十一大促期中,把优质评论精准展示,提高了商品页内容的有用度与转化率。
结果:
•平台发现“优质评论”引导下,用户浏览时长和下单转化率明显高于仅随机展示的对照组;
•进一步结合主观评测(MOS 评分)与用户行为数据,确认模型能持续输出较为理想的“优质评论列表”。
通过以上内容,我们可以看到大模型评测并非遥不可及。在借鉴传统机器学习评测方法的基础上,合理扩充大模型特有的评测维度(如对话连贯度、多模态数据处理、行业知识适配等),就能在“评什么、怎么评、评到什么程度”三个关键问题上给出清晰答案。
面对具体业务场景(如“手机产品用户评论打分,选择优秀评论优先展示”),我们既能沿用离线静态评测的客观指标,又能结合在线动态评测的用户行为反馈,辅以基于人工或更高级模型的主观打分,形成一套灵活、系统的评测框架。
这样的大模型评测路径既能及时发现模型短板,也能为后续持续迭代和优化提供可靠依据,从而在保证技术可行性的同时,真正让大模型在实际业务中落地生根、创造价值。
以上就是如何评测模型效果的全部内容,希望对大家有帮助。
评论区
暂无评论,快来发表第一条评论吧~